공부했던 자료 정리하는 용도입니다.
재배포, 수정하지 마세요.
예제는 Oracle Database에서 기본으로 제공되는 SCOTT계정 데이터로 진행됩니다.
오라클 데이터베이스는 데이터 보관 및 관리를 위한 여러 기능과 저장공간을 객체를 통해 제공한다.
객체 종류
- 테이블(table)
- SQL문
- 데이터 사전(data dictionary) : 데이터베이스 운영에 필요한 정보가 있는 특수 테이블
- 인덱스(index) : 데이터 검색 성능의 향상을 위해 테이블 열에 사용하는 객체
- 뷰(view) : 가상 테이블(virtual table), 하나이상의 테이블을 조회하는 SELECT 문을 저장한 객체
- 시퀀스(sequence) : 특정 규칙에 맞게 연속된 숫자를 생성하는 객체
- 동의어(synonym) : 테이블/뷰/시퀀스 등 객체 이름 대신 사용할 수 있는 다른 이름을 부여하는 객체
3. 데이터 사전(data dictionary)
-- SCOTT계정에서 사용 가능한 데이터 사전 조회(두 SELECT문은 같은 결과를 출력한다.)
SELECT * FROM DICT;
SELECT * FROM DICTIONARY;오라클 데이터베이스 테이블은 사용자 테이블(User table, Normal table)과 데이터 사전(Data dictionary, Base table)으로 나뉜다. 데이터 사전에 문제가 생기면 데이터베이스 사용이 불가능해질 수도 있기 때문에 사용자가 데이터 사전 정보에 직접 접근하거나 작업하는 것을 허용하지 않는다. 대신 데이터 사전 뷰(data dictionary view)를 제공하여 SELECT 문으로 정보 열람을 할 수 있다. 사용 가능한 데이터 사전을 알고 싶다면 위의 SQL문과 같이 DICTIONARY 또는 DICT 를 조회한다.
| 사용자 테이블 (User table, Normal table) |
데이터베이스를 통해 관리할 데이터를 저장하는 테이블 |
| 데이터 사전 (Data dictionary, Base table) |
데이터베이스 메모리·성능·사용자·권한·객체등 데이터베이스 운영에 필요한 모든 정보를 저장하는 특수한 테이블로 데이터베이스가 생성되는 시점에 자동으로 만들어진다.(데이터 사전에 문제가 생기면 데이터베이스 사용이 불가능해 질 수도 있다.) |
| 접두어 | 설 명 |
| USER_XXXX | 현재 데이터베이스에 접속한 사용자가 소유한 객체 정보 ex) 현재 오라클 데이터베이스에 접속해 있는 SCOTT 계정이 소유하는 테이블 정보는 USER_TABLES 를 사용한다. ( SELECT TABLE_NAME FROM USER_TABLES; ) |
| ALL_XXXX | 현재 데이터베이스에 접속한 사용자가 소유한 객체 또는 다른 사용자가 소유한 객체 중 사용허가를 받은 객체 → 사용 가능한 모든 객체 정보 ex) SCOTT계정으로 접속하여 ALL_TABLES 를 조회하면 SCOTT 계정이 사용할 수 있는 테이블 정보를 모두 보여준다. (SELECT OWNER, TABLE_NAME FROM ALL_TABLES;) ALL_TABLES 는 OWNER 열을 제외하면 USER_TABLES 와 동일한 열 구조를 가진다. ■ OWNER (VARCHAR2(30) / NOT NULL) : 테이블을 소유한 사용자를 명시( ALL_TABLES 에만 존재) ■ TABLE_NAME (VARCHAR(30) / NOT NULL) : 테이블 이름 ■ TABLESPACE_NAME (VARCHAR(30)) : 테이블 스페이스 이름 ■ NUM_ROWS (NUMBER) : 테이블에 저장된 행 수 + DUAL 테이블은 오라클 관리 계정 SYS 소유이고 SCOTT 계정은 이 테이블의 사용을 허가받은 것 ! |
| DBA_XXXX | 데이터베이스 운영·관리를 위한 정보(데이터베이스 관리 권한을 가진 SYSTEM , SYS 사용자만 열람 가능) + 보안문제상 오라클 데이터 베이스에서 어떤 사용자가 사용 권한이 없는 정보열람을 시도할 경우에는 해당 개체가 존재하지 않는다고 알려준다. ex) 데이터베이스에 존재하는 모든 테이블 출력 ( SELECT * FROM DBA_TABLES;) DBA_TABLES 역시 ALL_TABLES 와 열 구성이 같다. ex) DBA_USERS 로 데이터베이스에 등록된 사용자 정보를 조회할 수 있다. SCOTT 사용자 정보를 보는 경우 USERNAME 열을 WHERE 조건으로 지정하여 사용하면 된다. ( SELECT * FROM DBA_USERS WHERE USERNAME = 'SCOTT';) |
| V$_XXXX | 데이터베이스 성능 관련 정보(X$_XXXX 테이블의 뷰) |
데이터 사전 뷰는 용도에 따라 이름 앞에 접두어를 지정하여 분류하며, 접두어 뒤에는 보통 복수형의 단어가 온다.
데이터 사전에 저장된 데이터베이스 관리와 관련된 정보 소개, 또는 모든 열 정보가 필요하다면 오라클 공식문서를 참조하면 된다.
4. 인덱스(index)
-- 1) 계정이 소유한 인덱스 정보 조회
SELECT * FROM USER_INDEXES;
-- 2) 계정이 소유한 인덱스 컬럼 정보 조회
SELECT * FROM USER_IND_COLUMNS;인덱스는 오라클 데이터베이스에서 데이터 검색 성능의 향상을 위해 테이블 열에 사용하는 객체를 뜻하며, 테이블에 보관된 특정 열 데이터의 주소(위치정보)를 목록으로 만들어 놓은 것이다. 인덱스 사용 여부에 따라 데이터 검색 방식을 Full Scan, Index Scan으로 구분한다. 인덱스를 지정한다고 해서 데이터 조회를 반드시 빠르게 한다고 보장하기는 어려우며 인덱스의 무분별한 생성은 오히려 성능을 떨어뜨리는 원인이 되기도 한다. 인덱스는 데이터 종류, 분포도, 조회하는 SQL의 구성, 데이터 조작 관련 SQL문의 작업 빈도, 검색 결과가 전체 데이터에서 차지하는 비중 등 많은 요소를 고려해서 생성한다.
인덱스도 오라클 데이터베이스 객체이므로 소유 사용자와 사용권한이 존재한다. 계정 소유의 인덱스 정보를 열람할 때는 USER_INDEXES , USER_IND_COLUMNS 와 같은 데이터 사전을 사용한다.
■ 데이터 검색방식
- Full Scan : 테이블 데이터를 처음부터 끝까지 검색하여 데이터를 찾는 방식
- Index Scan : 인덱스를 통해 데이터를 찾는 방식


SCOTT 계정에서 인덱스를 조회한 결과이다. 결과를 보면 EMP 테이블의 EMPNO 열, DEPT 테이블의 DEPTNO 열에 인덱스가 이미 생성되어 있는 것을 확인할 수 있다. TABLE_NAME 열에서 인덱스가 속한 테이블을 확인할 수 있고, COLUMN_NAME 열에서 인덱스를 지정한 열을 알 수 있다. 인덱스는 사용자가 직접 특정 테이블의 열에 지정할 수도 있지만 열이 기본키(primary key) 또는 고유키(unique key)일 경우에 자동으로 생성된다.
■ 인덱스 생성
CREATE INDEX 인덱스 이름
ON 테이블 이름(열 이름1 ASC or DISC,
열 이름2 ASC or DISC,
... );
-- ex) EMP테이블의 SAL열에 인덱스 생성
CREATE INDEX IDX_EMP_SAL
ON EMP(SAL); -- 정렬옵션을 지정하지 않으면 기본값은 ASC(오름차순)
-- 생성된 인덱스 확인
SELECT * FROM USER_IND_COLUMNS;오라클 데이터베이스에서 자동으로 생성해 주는 인덱스 외에 사용자가 인덱스를 만들 경우 CREATE 문을 사용한다. CREATE 문에서는 인덱스를 생성할 테이블 및 열을 지정하며, 열은 하나 또는 여러 개 지정할 수 있다. 지정한 각 열 별로 인덱스 정렬 순서를 정할 수도 있다. (기본값은 오름차순( ASC ))

■ 인덱스의 종류
| 방 식 | 사 용 |
| 단일 인덱스(single index) | CREATE INDEX IDX_NAME ON EPM(SAL); |
| 복합 인덱스(concatenated index) 결합 인덱스(composite index) - 2개 이상의 열로 만들어지는 인덱스 - WHERE 절의 두 열이 AND 연산으로 묶이는 경우 |
CREATE INDEX IDX_NAME ON EMP(SAL, ENAME, ...); |
| 고유 인덱스(unique index) - 열에 중복 데이터가 없을 때 사용 - UNIQUE 키워드를 지정하지 않으면 비고유 인덱스(non unique index)가 기본값 |
CREATE UNIQUE INDEX IDX_NAME ON EMP(EMPNO); |
| 함수 기반 인덱스(function based index) - 열에 산술식 같은 데이터 가공이 진행된 결과로 인덱스 생성 |
CREATE INDEX IDX_NAME ON EMP(SAL*12 + COMM); |
| 비트맵 인덱스(bitmap index) - 데이터 종류가 적고 같은 데이터가 많이 존재할 때 주로 사용 |
CREATE BITMAP INDEX IDX_NAME ON EMP(JOB); |
■ 인덱스 삭제
DROP INDEX 인덱스 이름;
-- ex) 인덱스 삭제
DROP INDEX IDX_EMP_SAL;
-- 삭제된 인덱스 조회
SELECT * FROM USER_IND_COLUMNS;인덱스 삭제는 DROP 명령어를 사용한다.

5. 뷰(view)
가상 테이블(virtual table)이라고도 한다. 하나 이상의 테이블을 조회하는 SELECT 문을 저장한 객체를 뜻하며 SELECT 문을 저장하기 때문에 물리적 데이터를 따로 저장하지 않는다. 뷰를 이용하면 서브 쿼리를 사용한 것과 같은 결과를 낼 수 있고, SELECT 문의 FROM 절에 사용하면 특정 테이블을 조회하는 것과 같은 효과를 얻을 수도 있다.
+ 뷰는 데이터 열람이 주목적이지만 데이터 조작어 사용이 허용되는 구체화 뷰(materialized view)도 있다.
■ 뷰(view)의 사용 목적
- 편리성 : SELECT 문의 복잡도를 줄이기 위해
SQL문에서 자주 활용하는 SELECT 문을 뷰로 저장해 놓은 후 다른 SQL문에서 활용하면 전체 SQL문의 복잡도를 줄이고 원래 목적의 메인 쿼리에 집중할 수 있어 편리하다. - 보안성 : 테이블의 특정 열을 노출하고 싶지 않을 경우
주민등록번호같이 담당자 이외에 노출이 허용되지 않는 중요한 개인 정보 데이터가 존재할 경우 사용자에게 특정 테이블의 전체 조회 권한을 부여하는 것은 보안상 위험하다. 테이블의 일부 데이터 또는 조인이나 여러 함수 등으로 가공을 거친 데이터만 SELECT 하는 뷰 열람 권한을 제공하는 것이 불필요한 데이터 노출을 막을 수 있기 때문에 더 안전하다.
■ 뷰 생성
CREATE [OR REPLACE] [FORCE | NOFORCE] VIEW 뷰 이름 (열 이름1, 열 이름2, ...)
AS (저장 할 SELECT문)
[WITH CHECK OPTION [CONSTRAINT 제약 조건]]
[WITH READ ONLY [CONSTRAINT 제약 조건]]뷰를 생성할 때는 CREATE 문을 사용한다.
- OR REPLACE (선택) : 같은 이름의 뷰가 이미 존재할 경우에 현재 생성할 뷰로 대체하여 생성
- FORCE (선택) : 뷰가 저장할 SELECT 문의 기반 테이블이 존재하지 않아도 강제로 생성
- NOFORCE (선택) : 뷰가 저장할 SELECT 문의 기반 테이블이 존재할 경우에만 생성(DEFAULT)
- 뷰 이름(필수) : 생성할 뷰 이름을 지정
- 열 이름(선택) : SELECT 문에 명시된 이름 대신 사용할 열 이름 지정(생략 가능)
- 저장할 SELECT 문(필수) : 생성할 뷰에 저장할 SELECT 문 지정
- WITH CHECK OPTION (선택) : 지정한 제약 조건을 만족하는 데이터에 한해 DML 작업이 가능하도록 뷰 생성
- WITH READ ONLY (선택) : 뷰의 열람, 즉 SELECT 만 가능하도록 뷰 생성
-- 1) 뷰를 생성하기 위해 SQLPLUS에 SYSTEM계정으로 로그인, SCOTT계정에 뷰 생성권한 주기
$ SQLPLUS SYSTEM/oracle
GRANT CREATE VIEW TO SCOTT;
-- 2) SQL Developer에서 뷰 생성(SCOTT계정으로 로그인)
CREATE VIEW VW_EMP20
AS (SELECT EMPNO, ENAME, JOB, DEPTNO
FROM EMP
WHERE DEPTNO = 20);
-- 3)생성된 뷰에 저장된 SELECT문 조회
-- 3-1) SQL Developer에서 조회
SELECT *
FROM USER_VIEWS;
-- SQLPLUS로도 뷰에 저장된 SELECT문을 확인할 수 있다.
-- 3-2) SQLPLUS에서 조회
-- 1. CMD창에서 로그인
SQLPLUS SCOTT/tiger
-- 2. 뷰 내용 확인
SELECT VIEW_NAME, TEXT_LENGTH, TEXT
FROM UESR_VIEWS;
-- 4) 생성한 뷰 조회
SELECT *
FROM VW_EMP20;



SQL Developer나 SQLPLUS에서 USER_VIEWS 를 조회하면 VM_EMP20 뷰에 저장된 SELECT 문을 확인할 수 있다. 이렇게 생성한 뷰는 여러 가지로 활용할 수 있으며, 예제에 있는 간단한 SELECT 문 외에도 여러 테이블을 조인하거나 서브 쿼리를 사용한 복합적인 SELECT 문도 뷰에 저장할 수 있다.
■ 뷰 삭제
DROP VIEW VW_EMP20;뷰를 삭제할 때 DROP 문을 사용한다.
뷰는 실제 데이터가 아닌 SELECT 문만 저장하므로 뷰를 삭제해도 테이블이나 데이터가 삭제되는 것은 아니다
■ 인라인 뷰(inline view)
CREATE 문을 통해 객체로 만들어지는 뷰 외에 SQL문에서 일회성으로 만들어서 사용하는 뷰를 인라인 뷰(inline view)라고 한다. SELECT 문에서 사용되는 서브 쿼리, WITH 절에서 미리 이름을 정의해 두고 사용하는 SELECT 문 등이 이에 해당한다.
★ 인라인 뷰를 사용한 TOP-N SQL문
인라인 뷰와 ROWNUM 을 사용하면 ORDER BY 절을 통해 정렬된 결과 중 최상위 몇 개 데이터만을 출력하거나, 정렬된 SELECT 문에 결과 순번을 매겨서 출력하는 것이 가능하다.
- ROWNUM : 의사 열(pseudo column)이라고 하는 특수 열이다.
데이터를 하나씩 추가할 때 매겨지는 번호라서 ORDER BY 절을 통해 정렬해도 유지되는 특성이 있다. - 의사 열(pseudo column) : 데이터가 저장되는 실제 테이블에 존재하지는 않지만 특정 목적을 위해 테이블에 저장되어 있는 열처럼 사용 가능한 열을 뜻한다.
■ 인라인 뷰 활용
1) 정렬된 결과를 기준으로 ROWNUM 매기기
SELECT ROWNUM, E.*
FROM EMP E;위의 SQL문을 실행해보면 ROWNUM 열은 EMP 테이블에 존재하지 않지만 ROWNUM 열의 데이터가 숫자로 출력되는 것을 확인할 수 있다.
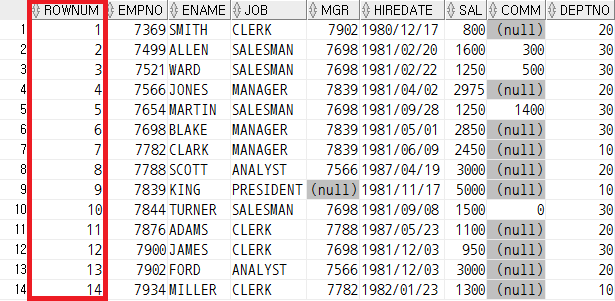
SELECT ROWNUM, E.*
FROM EMP E
ORDER BY SAL DESC;그러나 ROWNUM 은 데이터를 하나씩 추가할 때 매겨지는 번호이므로 ORDER BY 를 사용해서 정렬해도 유지되는 특성이 있다. (위의 SQL문은 급여( SAL )을 기준으로 내림차순 정렬한 것)정렬된 결과를 기준으로 ROWNUM 을 매기고 싶다면 서브 쿼리를 인라인 뷰로 사용한 SELECT 문이나, WITH 절에 인라인 뷰를 사용한 SELECT 문을 이용해야 한다.

-- 1) 서브쿼리를 인라인 뷰로 사용한 SELECT문
SELECT ROWNUM, E.*
FROM (SELECT *
FROM EMP
ORDER BY SAL DESC) E;
-- 2) WITH절에 인라인 뷰를 사용한 SELECT문
WITH E AS (SELECT * FROM EMP ORDER BY SAL DESC)
SELECT ROWNUM, E.*
FROM E;

ORDER BY 절로 된 SELECT 문의 데이터가 메인 쿼리의 SELECT 문에서 순서대로 ROWNUM 이 매겨져 정렬된 순서대로 번호가 매겨진 것을 확인할 수 있다.
2) ROWNUM을 이용한 조건식(인라인 뷰를 사용한 TOP-N 추출)
-- 1) 서브쿼리를 사용한 인라인 뷰로 TOP-N 추출
SELECT ROWNUM, E.*
FROM (SELECT *
FROM EMP
ORDER BY SAL DESC) E
WHERE ROWNUM <= 3;
-- 2) WITH절을 사용한 인라인 뷰로 TOP-N 추출
WITH E AS (SELECT * FROM EMP ORDER BY SAL DESC)
SELECT ROWNUM, E.*
FROM E
WHERE ROWNUM <= 3;정렬한 기준으로 ROWNUM 을 매긴 상태에서 WHERE 절에 ROWNUM 을 사용하면 상위 데이터만을 추출할 수 있다. 위의 두 SQL문은 급여가 높은 상위 세명의 데이터를 출력하는 예시이다.

6. 시퀀스(sequence)
시퀀스(sequence)는 특정 규칙에 맞게 연속된 숫자를 생성하는 객체이다.
■ 시퀀스 생성
CREATE SEQUENCE 시퀀스 이름
[INCREMENT BY n]
[START WITH n]
[MAXVALUE n | NOMAXVALUE]
[MINVALUE n | NOMINVALUE]
[CYCLE | NOCYCLE]
[CACHE n | NOCACHE]시퀀스는 CREATE 문으로 생성하며 여러 가지 옵션을 지정할 수 있다.
- 시퀀스 이름(필수) : 생성할 시퀀스 이름 지정.
아래의 옵션들을 지정하지 않았을 경우 1부터 시작하여 1만큼 계속 증가하는 시퀀스가 생성 - INCREMENT BY n (선택) : 시퀀스에서 생성할 번호의 증가 값(default는 1)
- START WITH n (선택) : 시퀀스에서 생성할 번호의 시작 값(default는 1)
- MAXVALUE (선택) : 시퀀스에서 생성할 번호의 최대값 지정.
최대값은 시작 값( START WITH )이상 최소값( MINVALUE )을 초과값으로 지정.
NOMAXVALUE 로 지정하였을 경우 오름차순이면 10^27, 내림차순일 경우 -1로 설정 - MINVALUE (선택) : 시퀀스에서 생성할 번호의 최소값 지정. 최소값은 시작값( START WITH )이하, 최대값( MAXVALUE )미만 값으로 지정.
NOMINVALUE 로 지정하였을 경우 오름차순이면 1, 내림차순이면 10^(-26)으로 설정 - CYCLE (선택) : 시퀀스에서 생성한 번호가 최대값( MAXVALUE )에 도달했을 경우 CYCLE 이면 시작 값( START WITH )에서 다시 시작 NOCYCLE 이면 번호 생성이 중단되고, 추가 번호 생성을 요청하면 오류 발생
- CACHE (선택) : 시퀀스가 생성할 번호를 메모리에 미리 할당해 놓은 수를 지정,
NOCACHE 는 미리 생성하지 않도록 설정. 옵션을 모두 생략하면 default 20
■ 시퀀스 사용
-- 1) DEPT테이블을 사용해서 시퀀스를 테스트할 DEPT_SEQUENCE테이블 생성
CREATE TABLE DEPT_SEQUENCE
AS SELECT *
FROM DEPT
WHERE 1 <> 1; // 1 <> 1은 항상 false이므로 데이터가 없는 빈 테이블이 생성된다.
-- 2) 생성한 DEPT_SEQUENCE테이블 확인
SELECT * FROM DEPT_SEQUENCE;
-- 3) 시퀀스 생성
CREATE SEQUENCE SEQ_DEPT_SEQUENCE -- 시퀀스 이름
INCREMENT BY 10 -- 시퀀스가 10씩 증가
START WITH 10 -- 시퀀스를 10부터 시작함
MAXVALUE 90 -- 시퀀스의 최대번호를 90으로 지정
MINVALUE 0 -- 시퀀스의 최소번호를 0으로 지정
NOCYCLE -- 시퀀스에서 생성한 번호가 MAXVALUE에 도달했을 경우 번호생성이 중단되고 추가번호생성을 요청하면 오류발생
CACHE 2; -- 시퀀스가 생성할 번호를 메모리에 미리할당해 놓은 수를 지정
-- 4) 생성한 시퀀스 확인
SELECT * FROM USER_SEQUENCES;시퀀스의 사용방법을 알아보는 예시이다. 시퀀스를 이용하기 위해서 빈 테이블과 시퀀스를 생성한다.


-- 1) 시퀀스에서 생성한 번호를 이용한 INSERT문
INSERT INTO DEPT_SEQUENCE(DEPTNO, DNAME, LOC)
VALUES (SEQ_DEPT_SEQUENCE.NEXTVAL, 'DATABASE', 'SEOUL');
-- 2) 결과 확인
SELECT * FROM DEPT_SEQUENCE ORDER BY DEPTNO;시퀀스를 사용할 때는 시퀀스 이름.CURRVAL 과 시퀀스 이름.NEXTVAL 을 사용한다.
위의 예시는 INSERT 문에 시퀀스를 사용해서 부서 번호를 입력하는 예시이다.
- CURRVAL : 시퀀스에서 마지막으로 생성한 번호를 반환
시퀀스를 생성하고 바로 쓰면 번호가 만들어진 적이 없어서 오류가 난다. (처음 사용할 때는 NEXTVAL 을 써야 한다.) - NEXTVAL : 시퀀스에서 다음 번호를 생성

START WITH 가 10 이고 INCREMENT BY 가 10 이기 때문에 DEPTNO 가 10 부터 시작해서 10 씩 증가하는 것을 확인할 수 있다.

또한 NOCYCLE 이기 때문에 10 번째 실행하면 오류가 난다.
옵션을 CYCLE 로 지정하면 MAXVALUE 를 넘었을 경우 다시 MINVALUE 값부터 시작해서 증가한다.
■ 시퀀스 수정
ALTER SEQUENCE 시퀀스 이름
[INCREMENT BY n]
[MAXVALUE n | NOMAXVALUE]
[MINVALUE n | NOMINVALUE]
[CYCLE | NOCYCLE]
[CACHE n | NOCACHE]
-- ex)
-- 1) 시퀀스 옵션을 수정
ALTER SEQUENCE SEQ_DEPT_SEQUENCE
INCREMENT BY 3 -- 증가값을 3으로 수정
MAXVALUE 99 -- 최대값을 99로 수정
CYCLE; -- 최대값에 도달했을 경우 START WITH값으로 돌아가서 다시 시퀀스가 돌도록 수정
-- 2) 수정된 시퀀스 조회
SELECT * FROM USER_SEQUENCES;ALTER 명령어로 시퀀스를 수정할 수 있다. 옵션을 재설정하는 데 사용하며 START WITH 값은 변경할 수 없다.

증가 값을 3 으로 수정했기 때문에 다음 시퀀스는 93 이 되는 것을 확인할 수 있다.
CYCLE 로 설정했기 때문에 최대값인 99 를 넘으면 MINVALUE 값인 0 부터 다시 값이 증가한다.
■ 시퀀스 삭제
DROP SEQUENCE SEQ_DEPT_SEQUENCE;
-- 시퀀스 삭제후 확인
SELECT * FROM USER_SEQUENCES;DROP 명령어를 사용해서 시퀀스를 삭제할 수 있다.
시퀀스를 삭제해도 시퀀스를 사용하여 추가된 데이터( SEQ_DEPT_SEQUENCES.NEXTVAL )는 삭제되지 않는다.
7. 동의어(synonym)
테이블·뷰·시퀀스 등 객체 이름 대신 사용할 수 있는 다른 이름을 부여하는 객체이다. 테이블 이름을 간단하게 할 때 주로 사용한다. 테이블 별칭(alias)과 비슷하지만 오라클 데이터베이스에 저장되는 객체이기 때문에 일회성이 아니라는 차이점이 있다. 동의어를 생성하기 위해서는 권한이 필요하며, 생성할 때는 CREATE 문을 이용한다. 생성한 동의어는 SELECT , INSERT , UPDATE , DELETE 등 다양한 SQL문에서 사용할 수 있다.
■ 동의어 생성 권한 부여
-- 권한 부여하기(SQLPLUS)
SQLPLUS SYSTEM/oracle -- SYSTEM계정 접속
GRANT CREATE SYNONYM TO SCOTT; -- SYNONYM 권한 부여
GRANT CREATE PUBLIC SYNONYM TO SCOTT; -- PUBLIC SYNONYM 권한 부여동의어를 생성하기 위해서는 SCOTT 계정에 권한을 부여해야 한다. 또한 PUBLIC SYNONYM 권한도 따로 부여해주어야 한다.
SYNONYM의 종류
- Private Synonym : 특정 사용자만 이용할 수 있다.
- Public Synonym : 공용 사용자 그룹이 소유하며 그 데이터베이스에 있는 모든 사용자가 공유한다.
■ 동의어 생성
CREATE SYNONYM E
FOR EMP;
-- 생성된 동의어를 사용해서 테이블 조회
SELECT * FROM E;CREATE 문으로 동의어를 생성할 수 있다.
생성하고 난 뒤 E 동의어로 SELECT 문을 실행하면 EMP 테이블의 데이터가 조회된다.
■ 동의어 삭제
DROP SYNONYM E;DROP 문을 사용하여 동의어를 삭제할 수 있다.
동의어를 삭제해도 본래 테이블 이름과 데이터에는 아무 영향도 주지 않는다.
'Back end > Database' 카테고리의 다른 글
| [Oracle] 사용자, 권한, 롤 관리 (0) | 2019.10.12 |
|---|---|
| [Oracle] 제약조건(constraint) (0) | 2019.10.08 |
| [Oracle] 데이터 정의어 (DDL : Data Definition Language) (0) | 2019.09.29 |
| [Oracle] 트랜잭션(transaction)과 TCL, 세션(session) (0) | 2019.09.24 |
| [Oracle] 데이터 조작어 (DML : Data Manipulation Language) (0) | 2019.09.18 |