공부했던 자료 정리하는 용도입니다.
재배포, 수정하지 마세요.
예제는 Oracle Database에서 기본으로 제공되는 SCOTT계정 데이터로 진행됩니다.
복합 자료형 (composite data type)
: 여러 종류 및 개수의 데이터를 저장하기 위해 사용자가 정의하는 자료형을 말한다.
- 레코드(RECORD) : 여러 종류 자료형의 데이터를 저장(테이블의 행과 유사)
- 컬렉션(TABLE) : 한 가지 자료형의 데이터를 여러 개 저장(테이블의 열과 유사)
레코드
TYPE [레코드 이름] IS RECORD(
[변수 이름] [자료형] NOT NULL [:= 또는 DEFAULT] [값 or 값이 도출되는 표현식]
)자료형이 다른 데이터를 하나의 변수에 저장하는 데 사용한다. 정의한 레코드는 변수와 마찬가지로 기존 자료형처럼 사용 가능하고 레코드에 포함된 변수는 [레코드 이름].[변수 이름] 으로 사용할 수 있다.
- [레코드 이름] : 저장할 레코드 이름 지정
- [변수 이름] : 레코드 안에 포함할 변수를 지정. 여러 개 지정할 때는 쉼표(,)로 구분
- [자료형] : 지정한 변수의 자료형을 지정. ( %TYPE , %ROWTYPE 지도 지정 가능)
%ROWTYPE : 행 구조 전체 참조
%TYPE : 열 참조 - NOT NULL (선택) : 지정한 변수에 NOT NULL 제약 조건 지정
- DEFAULT (선택) : 기본값 지정
DECLARE
TYPE REC_DEPT IS RECORD( -- 레코드 정의
deptno NUMBER(2) NOT NULL := 99, -- 레코드 안의 변수(deptno, dname, loc) 선언
dname DEPT.DNAME%TYPE, -- 열 참조
loc DEPT.LOC%TYPE
);
dept_rec REC_DEPT; -- 레코드 REC_DEPT를 자료형으로 하는 변수 dept_rec 선언
BEGIN
dept_rec.deptno := 99; -- 레코드안의 변수에 값 대입
dept_rec.dname := 'DATABASE';
dept_rec.loc := 'SEOUL';
DBMS_OUTPUT.PUT_LINE('DEPTNO : ' || dept_rec.deptno); -- 레코드 안의 변수들 출력
DBMS_OUTPUT.PUT_LINE('DNAMD : ' || dept_rec.dname);
DBMS_OUTPUT.PUT_LINE('LOC : ' || dept_rec.loc);
END;
/레코드를 정의하고 사용하는 예시이다.

■ 레코드를 이용한 INSERT
PL/SQL문에서는 테이블에 데이터를 삽입하거나 수정하는 INSERT , UPDATE 문에도 레코드를 사용할 수 있다. 기존 INSERT 문에서는 삽입할 데이터를 VALUES 절에 하나씩 명시했지만 레코드를 이용할 때는 VALUES 절에 레코드 이름만 명시해 주면 된다. (선언한 레코드와 INSERT 대상이 되는 테이블의 데이터 개수, 자료형, 순서를 맞춰주어야 제대로 실행된다.)
-- 1) 레코드를 사용할 테이블인 DEPT_RECORD 만들기
CREATE TABLE DEPT_RECORD
AS SELECT * FROM DEPT;
-- 2) 레코드를 이용하여 INSERT
DECLARE
TYPE REC_DEPT IS RECORD( -- 레코드 선언
deptno NUMBER(2) NOT NULL := 99, -- 레코드 안의 변수(deptno, dname, loc) 지정
dname DEPT.DNAME%TYPE, -- 열 참조
loc DEPT.LOC%TYPE
);
dept_rec REC_DEPT; -- 레코드 REC_DEPT를 자료형으로 하는 dept_rec 선언
BEGIN
dept_rec.deptno := 99; -- 레코드 안의 변수 값 지정
dept_rec.dname := 'DATABASE';
dept_rec.loc := 'SEOUL';
INSERT INTO DEPT_RECORD -- 레코드를 이용한 INSERT (VALUES절에 레코드 이름만 명시하면 됨)
VALUES dept_rec; -- dept_rec에 저장된 변수 값들을 테이블에 삽입
END;
/
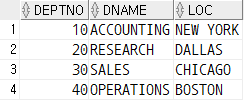
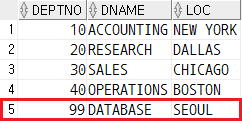
레코드 안의 변수 값들이 테이블에 삽입된 것을 확인할 수 있다.
■ 레코드를 이용한 UPDATE
UPDATE 문에도 레코드를 사용할 수 있다. 기존 UPDATE 문에서는 SET 절에 변경할 열을 하나하나 지정해 주어야 했지만 레코드를 이용하면 행 전체의 데이터를 한꺼번에 바꿔줄 수 있어 편리하다. SET 절에 ROW 키워드와 함께 레코드 이름을 명시하기만 하면 된다.
DECLARE
TYPE REC_DEPT IS RECORD( -- 레코드 선언
deptno NUMBER(2) NOT NULL := 99, -- 레코드 안의 변수(deptno, dname, loc) 선언
dname DEPT.DNAME%TYPE, -- 열 참조
loc DEPT.LOC%TYPE
);
dept_rec REC_DEPT; -- 레코드 REC_DEPT를 자료형으로 하는 변수 dept_rec 선언
BEGIN
dept_rec.deptno := 50; -- 레코드 안의 변수에 값 지정
dept_rec.dname := 'DB';
dept_rec.loc := 'SEOUL';
UPDATE DEPT_RECORD -- 레코드를 이용한 UPDATE
SET ROW = dept_rec -- dept_rec에 저장된 변수들 값으로 데이터 변경
WHERE DEPTNO = 99; -- DEPTNO가 99인 데이터에 적용
END;
/

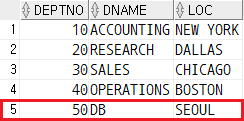
레코드 안의 변수 값들로 테이블이 변경된 것을 확인할 수 있다.
■ 레코드를 포함하는 레코드
레코드도 자료형이기 때문에 레코드에 포함된 변수의 자료형을 지정할 때 다른 레코드를 지정할 수도 있다. 이렇게 레코드 안에 또 다른 레코드를 포함한 형태를 중첩 레코드(nested record)라고 한다.
DECLARE
TYPE REC_DEPT IS RECORD( -- 레코드 REC_DEPT 선언
deptno DEPT.DEPTNO%TYPE, -- 레코드 안의 변수(deptno, dname, loc) 선언
dname DEPT.DNAME%TYPE, -- 열 참조
loc DEPT.LOC%TYPE
);
TYPE REC_EMP IS RECORD( -- 레코드 REC_EMP 선언
empno EMP.EMPNO%TYPE, -- 레코드 안의 변수(empno, ename, dinfo) 선언
ename EMP.ENAME%TYPE, -- 열 참조
dinfo REC_DEPT -- dinfo의 자료형을 레코드인 REC_DEPT로 선언
);
emp_rec REC_EMP; -- 레코드 REC_EMP를 자료형으로 하는 emp_rec 선언
BEGIN
SELECT E.EMPNO, E.ENAME, D.DEPTNO, D.DNAME, D.LOC
INTO emp_rec.empno, emp_rec.ename, -- SELECT문으로 불러온 결과들을 레코드 안의 변수들에게 대입
emp_rec.dinfo.deptno,
emp_rec.dinfo.dname,
emp_rec.dinfo.loc
FROM EMP E, DEPT D
WHERE E.DEPTNO = D.DEPTNO
AND E.EMPNO = 7788;
DBMS_OUTPUT.PUT_LINE('EMPNO : ' || emp_rec.empno); -- 레코드 안의 변수들 출력
DBMS_OUTPUT.PUT_LINE('ENAME : ' || emp_rec.ename);
DBMS_OUTPUT.PUT_LINE('DEPTNO : ' || emp_rec.dinfo.deptno);
DBMS_OUTPUT.PUT_LINE('DNAME : ' || emp_rec.dinfo.dname);
DBMS_OUTPUT.PUT_LINE('LOC : ' || emp_rec.dinfo.loc);
END;
/

중첩 레코드안의 변수를 불러올 때는 [레코드 1].[레코드 2].[변수 이름] 형식으로 불러온다.
( 레코드 1 안의 변수가 레코드 2 를 자료형으로 사용할 때)
컬렉션
컬렉션은 특정 자료형의 데이터를 여러 개 저장하는 복합 자료형이다. 레코드를 테이블의 한 행처럼 사용한다면 컬렉션은 열 또는 테이블과 같은 형태로 사용할 수 있다. 연관 배열이 컬렉션 중 사용빈도가 가장 높다.
PL/SQL에서 사용할 수 있는 컬렉션
- 연관 배열(associative array (or index by table))
- 중첩 테이블(nested table)
- VARRAY(variable-size array)
■ 연관 배열
TYPE [연관 배열 이름] IS TABLE OF [자료형] [NOT NULL]
INDEX BY [인덱스형];연관 배열은 인덱스라고도 불리며 키(key), 값(value)으로 구성되는 컬렉션이다. 중복되지 않은 유일한 키를 통해 값을 저장하고 불러오는 방식을 사용한다. 연관 배열을 정의할 때는 자료형이 TABLE 인 변수를 선언하면 되고, 작성한 연관 배열은 레코드와 마찬 가지로 특정 변수의 자료형으로서 사용할 수 있다.
- [연관 배열 이름] : 작성할 연관 배열 이름 지정
- [자료형] : 연관 배열 열에 사용할 자료형 지정.
사용 가능한 자료형
- 단일 자료형 ex) VARCHAR2 , DATE , NUMBER
- 참조 자료형 ex) %TYPE , %ROWTYPE
NOT NULL (선택) : 자료형에 지정하는 옵션 - [인덱스형] : 키로 사용할 인덱스의 자료형 지정
사용 가능한 자료형
- 정수 자료형 ex) BINARY_INTEGER , PLS_INTEGER
- 문자 자료형 ex) VARCHAR2
DECLARE
TYPE ITAB_EX IS TABLE OF VARCHAR2(20) -- 연관 배열 ITAB_EX 선언
INDEX BY PLS_INTEGER; -- 인덱스형을 정수로 선언
text_arr ITAB_EX; -- 연관 배열 ITAB_EX을 자료형으로 하는 변수 text_arr 선언
BEGIN
text_arr(1) := '1st data'; -- 연관 배열에 순서대로 값 대입
text_arr(2) := '2nd data';
text_arr(3) := '3rd data';
text_arr(4) := '4th data';
DBMS_OUTPUT.PUT_LINE('text_arr(1) : ' || text_arr(1)); -- 연관 배열의 값들을 출력
DBMS_OUTPUT.PUT_LINE('text_arr(2) : ' || text_arr(2));
DBMS_OUTPUT.PUT_LINE('text_arr(3) : ' || text_arr(3));
DBMS_OUTPUT.PUT_LINE('text_arr(4) : ' || text_arr(4));
END;
/연관 배열은 다른 프로그래밍 언어들의 배열과 사용 방식이 비슷하다.
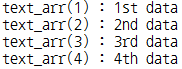
■ 레코드를 활용한 연관 배열
연관 배열의 자료형에 레코드를 사용할 수 있다. 이 경우에 다양한 자료형을 포함한 레코드를 여러 개 사용할 수 있어 마치 테이블과 같은 데이터 사용과 저장이 가능하다.
DECLARE
TYPE REC_DEPT IS RECORD( -- 레코드 REC_DEPT 선언
deptno DEPT.DEPTNO%TYPE, -- 레코드 안의 변수(deptno, dname) 선언
dname DEPT.DNAME%TYPE
);
TYPE ITAB_DEPT IS TABLE OF REC_DEPT -- 자료형이 레코드(REC_DEPT)인 연관 배열 ITAB_DEPT 선언
INDEX BY PLS_INTEGER; -- 인덱스형을 정수로 선언
dept_arr ITAB_DEPT; -- 자료형을 연관 배열인 ITAB_DEPT로 하는 변수 dept_arr 선언
idx PLS_INTEGER := 0;
BEGIN
FOR i IN (SELECT DEPTNO, DNAME FROM DEPT) LOOP -- FOR LOOP문에 IN을 쓰면 해당 테이블의 행 수 만큼 반복
idx := idx + 1;
dept_arr(idx).deptno := i.DEPTNO; -- SELECT문에서 조회한 결과를 dept_arr안의 변수에 대입
dept_arr(idx).dname := i.DNAME;
DBMS_OUTPUT.PUT_LINE(dept_arr(idx).deptno || ' : ' || dept_arr(idx).dname); -- 결과 출력
END LOOP;
END;
/레코드를 활용한 연관 배열의 예시이다.
DECLARE
TYPE ITAB_DEPT IS TABLE OF DEPT%ROWTYPE -- DEPT 테이블의 행 전체를 참조하는 연관 배열 ITAB_DEPT 선언
INDEX BY PLS_INTEGER; -- 인덱스형을 정수로 선언
dept_arr ITAB_DEPT; -- 자료형을 연관 배열인 ITAB_DEPT로 하는 변수 dept_arr 선언
idx PLS_INTEGER := 0;
BEGIN
FOR i IN(SELECT * FROM DEPT) LOOP -- FOR LOOP문에 IN을 쓰면 해당 테이블의 행 수 만큼 반복
idx := idx + 1;
dept_arr(idx).deptno := i.DEPTNO; -- SELECT문에서 조회한 결과를 dept_arr안의 변수에 대입
dept_arr(idx).dname := i.DNAME;
dept_arr(idx).loc := i.LOC;
DBMS_OUTPUT.PUT_LINE( -- 결과 출력
dept_arr(idx).deptno || ' : ' ||
dept_arr(idx).dname || ' : ' ||
dept_arr(idx).loc);
END LOOP;
END;
/만약 특정 테이블의 전체 열과 같은 구성을 가진 연관 배열을 제작한다면 위와 같이 %ROWTYPE 을 사용하는 것이 레코드를 정의하는 것보다 간편하다. (위와 같은 방식은 커서를 사용할 때도 동일하게 적용할 수 있다.)

■ 컬렉션 메서드
컬렉션 사용상의 편의를 위해 오라클에서 제공하는 메서드들을 컬렉션 메서드라고 한다. 컬렉션과 관련된 다양한 정보를 조회하는 것도 가능하고 컬렉션 내의 데이터 삭제나 컬렉션 크기 조절을 위한 특정 조작도 가능하다. 컬렉션 메서드는 컬렉션 형으로 선언한 변수에 마침표(.)와 함께 쓸 수 있다.
| 메서드 | 설 명 |
| EXISTS(n) | 컬렉션에서 n 인덱스의 데이터 존재 여부를 true / false 로 반환 |
| COUNT | 컬렉션에 포함되어 있는 요소 개수를 반환 |
| LIMIT | 현재 컬렉션의 최대 크기 반환 최대 크기가 없으면 NULL 반환 |
| FIRST | 컬렉션의 첫 번째 인덱스 번호 반환 |
| LAST | 컬렉션의 마지막 인덱스 번호 반환 |
| PRIOR(n) | 컬렉션에서 n 인덱스 바로 앞 인덱스 값을 반환 대상 인덱스 값이 존재하지 않으면 NULL 을 반환 |
| NEXT(n) | 컬렉션에서 n인덱스 바로 다음 인덱스 값을 반환 대상 인덱스 값이 존재하지 않는다면 NULL 을 반환 |
| DELETE | 컬렉션에 저장된 요소를 지우는데 사용 - DELETE : 컬렉션에 저장되어 있는 모든 요소 삭제 - DELETE(n) : n 인덱스의 컬렉션 요소를 삭제 - DELETE(n, m) : n 인덱스 ~ m 인덱스 까지 요소를 삭제 |
| EXTEND | 컬렉션 크기를 증가시킴. 연관 배열을 제외한 중첩 테이블과 VARRAY 에서 사용 |
| TRIM | 컬렉션 크기를 감소시킴. 연관 배열을 제외한 중첩 테이블과 VARRAY 에서 사용 |
DECLARE
TYPE ITAB_EX IS TABLE OF VARCHAR2(20) -- 연관 배열인 ITAB_EX 선언 (자료형은 VARCHAR2(20))
INDEX BY PLS_INTEGER; -- 인덱스형을 정수로 선언
text_arr ITAB_EX; -- 자료형을 연관 배열인 ITAB_EX로 하는 변수 text_arr 선언
BEGIN
text_arr(1) := '1st data';
text_arr(2) := '2nd data';
text_arr(3) := '3rd data';
text_arr(50) := '50th data';
DBMS_OUTPUT.PUT_LINE('text_arr.COUNT : ' || text_arr.COUNT);
DBMS_OUTPUT.PUT_LINE('text_arr.FIRST : ' || text_arr.FIRST);
DBMS_OUTPUT.PUT_LINE('text_arr.LAST : ' || text_arr.LAST);
DBMS_OUTPUT.PUT_LINE('text_arr.PRIOR(50) : ' || text_arr.PRIOR(50));
DBMS_OUTPUT.PUT_LINE('text_arr.NEXT(50) : ' || text_arr.NEXT(50));
END;
/컬렉션 메서드를 사용하는 예시이다.

text_arr.NEXT(50) 은 50 번 인덱스의 다음 인덱스가 존재하지 않아 NULL 이 반환된 것이다. 그래서 출력하면 값이 비어있는 상태로 출력된다.
'Back end > Database' 카테고리의 다른 글
| [Oracle] 저장 서브프로그램 - 저장 프로시저(stored procedure), 함수(function) (0) | 2019.10.22 |
|---|---|
| [Oracle] PL/SQL - 커서(cursor)와 예외 처리 (0) | 2019.10.21 |
| [Oracle] PL/SQL - 조건 제어문, 반복 제어문, 순차 제어문 (0) | 2019.10.18 |
| [Oracle] PL/SQL (0) | 2019.10.16 |
| [Oracle] 사용자, 권한, 롤 관리 (0) | 2019.10.12 |