공부했던 자료 정리하는 용도입니다.
재배포, 수정하지 마세요.
- 자료구조(data structure) : 자료들을 정리하여 보관하는 여러 가지 구조
- 알고리즘(algorithm) : 컴퓨터로 문제를 풀기 위한 단계적인 절차, 특정한 일을 수행하는 명령어들의 집합
알고리즘이 되기 위한 조건
- 입력 : 0개 이상의 입력이 존재해야 함
- 출력 : 1개 이상의 출력이 존재해야 함
- 명백성 : 각 명령어의 의미는 모호하지 않고 명확해야 한다.
- 유한성 : 한정된 수의 단계 후에는 반드시 종료되어야 한다.
- 유효성 : 각 명령어들은 컴퓨터로 실행 가능한 연산이어야 한다.
알고리즘을 기술하는 방법
- 자연어
ex) 한글, 영어 - 흐름도(flowchart)
- 의사코드(pseudo-code)
대입 연산자를 ←로 사용한다는 점이 다름 - 프로그래밍 언어
알고리즘의 성능 분석
- 수행 시간 측정 방법 : ``time.h``헤더의 ``clock( )``함수를 이용해서 호출 프로세스에 의하여 사용된 CPU 시간을 계산
- 알고리즘이 복잡한 경우 테스트하기가 어려움
- 여러 가지 알고리즘을 비교하는 경우 반드시 똑같은 하드웨어를 사용하여 수행 시간을 측정해야 함
- 소프트웨어 환경에 따라 결과가 달라질 수 있음
ex) 일반적으로 컴파일 언어가 인터프리터 언어보다 빠름
- 테스트하지 않은 입력에 대해서는 수행 시간을 보장할 수 없음 - 알고리즘의 복잡도 분석 방법(complexity analysis)
: 대부분의 경우 알고리즘의 복잡도는 시간 복잡도를 의미한다.- 시간 복잡도(time complexcity)
- 알고리즘의 수행 시간 분석.
- 절대적인 수행 시간이 아닌 알고리즘을 이루고 있는 연산들이 몇 번 수행되는지 숫자로 표시한다.
- (보통 입력 값에 따라 수행 횟수가 변하게 되므로)연산의 수를 입력의 개수 n의 함수로 나타낸 것을 시간 복잡도 함수라고 하고 $T(n)$이라고 표기한다. - 공간 복잡도(space complexity) : 알고리즘이 사용하는 기억공간 분석
- 시간 복잡도(time complexcity)
빅오(big O) 표기법

| 두 개의 함수 $f(n)$과 $g(n)$이 주어졌을 때 모든 $n > n_0$에 대하여 |f(n)| <= c|g(n)|을 만족하는 2개의 상수 c와 $n_0$가 존재하면 f(n)=O(g(n))이다. |
- n의 값에 따른 함수의 상한 값을 나타내는 방법이다.
- 시간 복잡도 함수에서 불필요한 정보(함수의 증가에 별로 기여하지 못하는 항을 생략)를 제거한 것으로, 알고리즘 분석을 쉽게 할 목적으로 사용한다.
- 다항식으로 표현되었을 경우 다항식의 최고 차항만을 남기고 다른 항들과 상수항을 버리는 방법으로 간단하게 구할 수 있다. (logn은 생략하면 X)
- 최소 차수 함수로 표기되었을 경우만 의미가 있다.
- 상한을 표기한 것이므로 상한이 여러 개가 존재하는 경우에 문제
빅 오메가(big omega) 표기법

| 두 개의 함수 $f(n)$과 $g(n)$이 주어졌을 때 모든 $n > n_0$에 대하여 |f(n)| >= c|g(n)| 을 만족하는 2개의 상수 c와 $n_0$가 존재하면 f(n)=Ω(g(n))이다. |
n의 값에 따른 함수의 하한 값을 나타내는 방법이다.
빅 세타(big theta) 표기법

| 두 개의 함수 $f(n)$과 $g(n)$이 주어졌을 때 모든 $n > n_0$에 대하여 c1|g(n)| <= |f(n)| <= c2|g(n)|을 만족하는 3개의 상수 c1, c2와 $n_0$가 존재하면 f(n)=Θ(g(n))이다. |
- 동일한 함수로 상한과 하한을 만들 수 있는 경우에 사용할 수 있는 방법이다.
- 3가지 표기법 중 가장 정밀하다.
시간 복잡도 함수의 수행 시간(빅오 표기법)
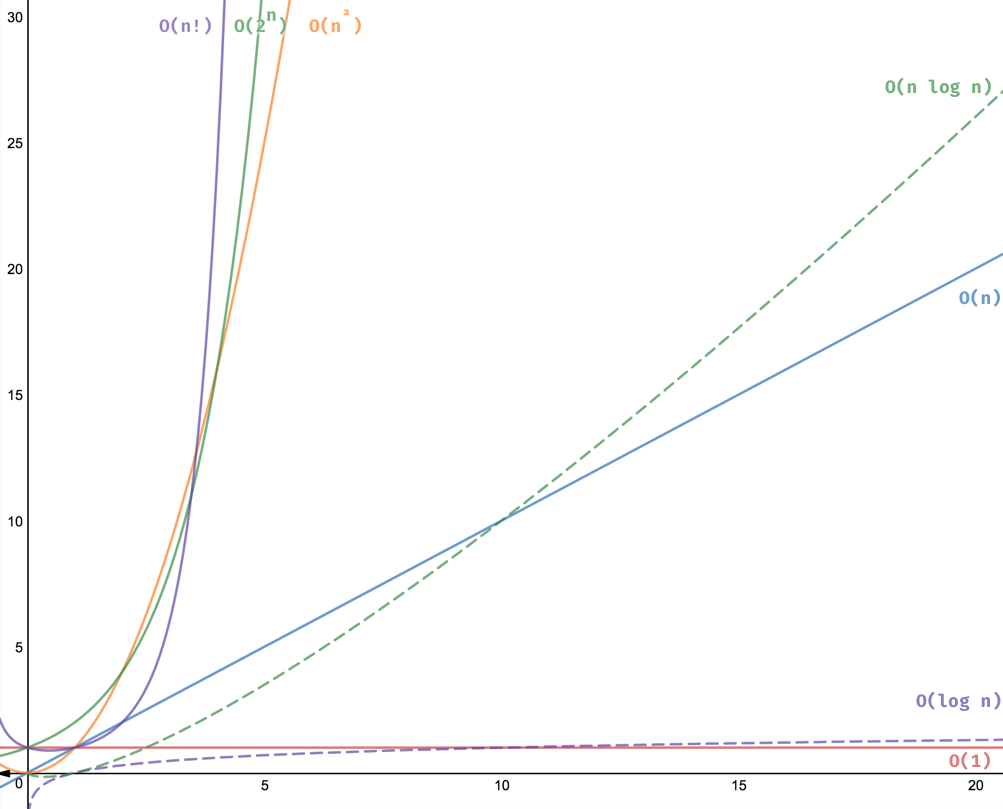
| 수행시간 $O(1) < O(logn) < O(n) < O(nlogn) < O(n^2) < O(2^n) < O(n!)$ |
- $O(1)$ : 상수형
- $O(log n)$ : 로그형
- $O(n)$ : 선형
- $O(nlogn)$ : 선형 로그형
- $O(n^2)$ : 2차형
- $O(n^3)$ : 3차형
- $O(2^n)$ : 지수형
- $O(n!)$ : 팩토리얼형
최선, 평균, 최악의 경우
똑같은 알고리즘도 주어지는 입력에 따라 수행시간이수행 시간이 달라질 수 있다. 평균적인 경우는 산출하기 어렵기 때문에 대부분 최악의 경우의 수행 시간이 알고리즘의 시간 복잡도 척도로 많이 사용된다.
- 최선의 경우(best case) : 수행시간이 가장 적은 경우
- 평균적인 경우(average case) : 알고리즘의 모든 입력과 각 입력이 발생하는 확률을 고려한 평균적인 수행시간
- 최악의 경우(worst case) : 자료 집합 중에서 알고리즘의 수행 시간이 가장 오래 걸리는 경우
추상화(abstraction)
- 어떤 시스템의 간략화된 기술, 또는 명세로서 시스템의 핵심적인 구조나 동작에만 집중하는 것.
- 좋은 추상화는 사용자에게 중요한 정보는 강조되고 중요하지 않은 구현 세부 사항은 제거되는 것이다. 이를 위하여 정보 은닉 기법(information hiding)이 개발되었고 추상 자료형의 개념으로 발전되었다.
추상 자료형(ADT : abstract data type)
- 자료형을 추상적으로 정의한 것
- 데이터나 연산이 무엇인지는 정의되지만 어떻게 컴퓨터 상에서 구현할 것인지는 정의되지 않는다.
- ADT안에는 객체(objects)와 함수(functions)들이 정의된다.
- 함수에는 매개변수, 반환형, 함수가 수행하는 기능의 기술 등이 포함된다.
- ``::=``는 "~으로 정의된다"는 의미이다. - 정보은닉의 한 방법으로도 사용된다.
: ADT가 구현될 때 보통 구현 세부사항은 외부에 알리지 않고 외부와의 인터페이스만을 공개하게 된다. ADT의 사용자는 구현 세부사항이 아닌 인터페이스만 사용하기 때문에 추상 자료형의 구현 방법은 언제든지 안전하게 변경될 수 있다. 또한 인터페이스만 정확하게 지켜진다면 ADT가 여러 가지 방법으로 구현될 수 있다. - 객체 지향 언어에서는 클래스 개념을 사용하여 ADT를 구현한다.
- ADT의 객체는 클래스의 속성, 연산은 클래스의 멤버 함수로 구현된다.
- private나 protected 키워드를 이용하여 내부 자료의 접근을 제한할 수 있다.
- 클래스는 계층구조(상속 개념 사용)로 구성될 수 있다.
기본 자료형
- 기초 자료형 : char, int, float, double ...
- 파생 자료형 : 배열, 포인터
- 사용자 정의 자료형 : 구조체, 공용체, 열거형
'기타 > 자료구조' 카테고리의 다른 글
| [자료구조] 우선순위 큐(priority queue), 힙(heap) (0) | 2021.07.17 |
|---|---|
| [자료구조] 트리, 이진 트리, 이진 탐색 트리 (0) | 2021.06.18 |
| [자료구조] 큐(Queue), 덱(Deque) (0) | 2021.02.02 |
| [자료구조] 스택(Stack) (0) | 2021.01.26 |
| 순환 알고리즘 (0) | 2021.01.25 |