공부했던 자료 정리하는 용도입니다.
재배포, 수정하지 마세요.
해싱과 해시함수
해싱은 해시함수(hash function)를 이용해서 데이터를 해시 테이블(hash table)에 저장하고 검색하는 기법을 말한다. 해시함수는 데이터가 저장되어 있는 곳을 알려주기 때문에 다량의 데이터 중에서도 원하는 데이터를 빠르게 찾을 수 있다. 해싱을 구현한 컬렉션 클래스로는 HashSet , HashMap , Hashtable 등이 있다. ( Hashtable 은 호환성 문제로 남겨진 것이기 때문에 HashMap 을 사용하는 것이 좋다.) 해싱에서 자용하는 자료구조는 배열과 링크드 리스트의 조합으로 되어있다. 저장할 데이터의 키를 해시함수에 넣으면 배열의 한 요소를 얻게 되고, 다시 그곳에 연결되어 있는 링크드 리스트에 저장하게 된다.
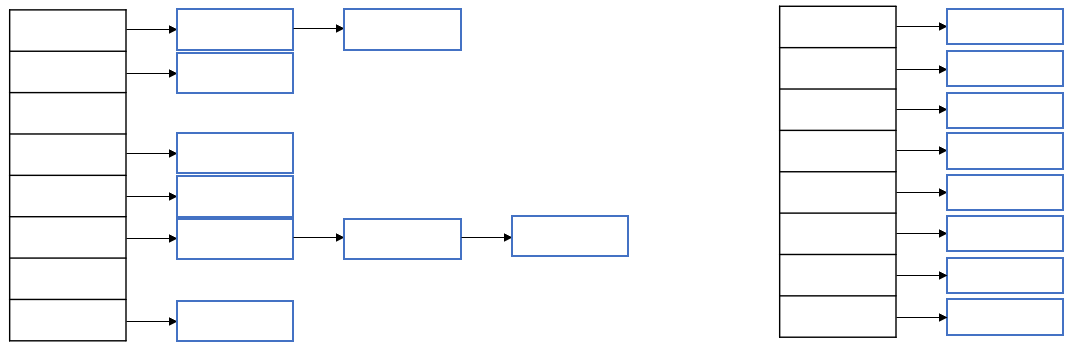
하지만 링크드 리스트는 검색에 불리한 자료구조이기 때문에 링크드 리스트의 크기가 커질수록 검색속도가 떨어지게 된다. 배열은 배열의 크기가 커져도, 원하는 요소가 몇 번째에 있는 지만 알면 아래의 공식에 의해서 빠르게 원하는 값을 찾을 수 있다. 그래서 하나의 배열에 많은 데이터가 저장되어 있는 형태보다 하나의 배열에 하나의 데이터만 저장되어 있는 형태가 더 빠른 검색 결과를 얻을 수 있다. 하나의 링크드 리스트에 최소한의 데이터만 저장되려면, 저장될 데이터의 크기를 고려해서 HashMap 의 크기를 적절하게 지정해주어야 하고, 해시함수가 서로 다른 키에 대해서 중복된 해시 코드의 반환을 최소화해야 한다. 그래야 빠른 검색시간을 얻을 수 있다.
실제로는 HashMap 과 같이 해싱을 구현한 컬렉션 클래스에서는 Object 클래스에 정의된 hashCode( ) 를 해시함수로 사용한다. Object 클래스에 정의된 hashCode( ) 는 객체의 주소를 이용하는 알고리즘으로 해시 코드를 만들어 내기 때문에 모든 객체에 대해 hashCode( ) 를 호출한 결과가 서로 유일하다.
String 클래스의 경우 Object 로부터 상속받은 hashCode( ) 를 오버 라이딩해서 문자열의 내용으로 해시 코드를 만들어낸다. 그래서 서로 다른 String 인스턴스일지라도 같은 내용의 문자열을 가졌다면 hashCode( ) 를 호출했을 때 같은 해시 코드를 얻는다. 서로 다른 두 객체에 대해 equals( ) 로 비교한 결과가 true 인 동시에 hashCode( ) 의 반환 값이 같아야 같은 객체로 인식한다. HashMap 에서도 같은 방법으로 객체를 구별하며, 이미 존재하는 키에 대한 값을 저장하면 기존의 값을 새로운 값으로 덮어쓴다.
그래서 새로운 클래스를 정의할 때 equals( ) 를 오버 라이딩해야 한다면 hashCode( ) 도 같이 재정의해서 equals( ) 의 결과가 true 인 두 객체의 hashCode( ) 의 결과값이 항상 같도록 해주어야 한다. 그렇지 않으면 HashMap 과 같이 해싱을 구현한 컬렉션 클래스에서는 equals( ) 의 호출 결과가 true 지만 해시 코드가 다른 두 객체를 서로 다른 것으로 인식하고 따로 저장한다.
'Back end > Java' 카테고리의 다른 글
| [Java] 지네릭스(Generics) (0) | 2019.07.29 |
|---|---|
| [Java] Properties, Collections (0) | 2019.07.26 |
| [Java] HashMap과 Hashtable, TreeMap (0) | 2019.07.25 |
| [Java] HashSet, TreeSet (0) | 2019.07.24 |
| [Java] Iterator, Arrays, Comparator (0) | 2019.07.23 |